
Last Updated November 23, 2022 ago | Published: March 4, 2022
If you’ve waded into the waters of artificial intelligence (AI), you’ve probably heard the term “machine learning” but what does it mean? Why is it important? Read on to learn all about this computing process and learn how you can use it for your business.
Complex issues like understanding how neural networks work within the context of deep learning can be difficult to fully grasp, especially if you, like me, don’t have the most technical background. But even those with strong data science backgrounds can get lost in the details. So we’ll break down the concept of a machine learning model into more manageable steps.
What exactly is machine learning?
Machine learning is a subset of artificial intelligence (AI) that involves analyzing computer algorithms and finding patterns from that data. In machine learning, data scientists train machines to sift through relevant data sets to solve specific problems.
In a typical day, the average person might use several different machine learning systems. These could be simple applications, like turning on a Roomba vacuum to clean their room. Or you could use machine learning for more complex tasks, like identifying your voice to analyze millions of web pages when you ask Siri to find “coffee near me.” Machine learning can provide everything from the data for programming a self-driving car to telling writers which topics they should pick for their next article. But even though machine learning seems new and modern, it’s based in the work of scientists from hundreds of years ago.
When did machine learning start?
The first instances of machine learning go back to 1763 when Thomas Bayes wrote the essay that Adrien-Marie LeGrande expounded upon to create Bayes Theorem in 1812. This theorem describes the probability of outcomes based on prior knowledge of relevant conditions, laying the groundwork for machine learning. It quantifies how you can make predictions based upon large patterns in data.
In the years after WWII Alan Turing, considered the Father of Computer Science, applied this principle within the context of machines. He gave a 1947 lecture describing a “machine that can learn from experience.” Three years later, he developed his own learning machine, an ancestor of the modern computer. In 1952, Arthur Samuel wrote the first learning program for IBM, involving a checkers game, and later coined the term “machine learning” in 1959.
Other computer scientists in the 1950s and 1960s also contributed to the field of machine learning with machines that could play other games like tic-tac-toe, evolving to designing machines that could identify map routes. Today, with advances like neural networks within deep machine learning, machines can function similarly to the human brain. These machine learning models have evolved to the point where they can predict patterns in human behavior, like voice and facial recognition.
What’s the difference between AI and machine learning?
The father of artificial intelligence, John McCarthy, defines AI as “the science and engineering of making intelligent machines, especially intelligent computer programs.” For McCarthy, artificial related to computers, and intelligence was the ability to achieve goals, so AI could also be considered a way that computers assist humans in reaching a specific goal.
Machine learning takes this concept a bit deeper. It’s a subset of AI that allows computers to learn from data and patterns without being programmed to do so explicitly. So the machines can start learning on their own, often from analyzing patterns in various data sets. They make predictions by observing data. As a result of this machine automation, companies that use machine learning notice an uptick in human productivity.
What are some examples of machine learning?
The Google algorithms are some of the most widely-used examples of machine learning techniques. Google trained its machines to scour all of the massive amounts of websites online, and recognize patterns. Its machine learning algorithms use natural language processing to break down the context of larger articles. Thanks to advances in machine learning technology, when you search up some terms, you’re more likely to get relevant data placed in proper context, rather than random pages stuffed with keywords.
Some of its algorithms offer personalization, for example, with location tracking, if you search for “Pizza near me” the input from the algorithm has been trained to identify map patterns and location, so it can predict the right place to send users. Or automatic speech recognition that helps propel the Internet of Voice represents other types of machine learning mechanisms.
Are there different types of machine learning?
Machine learning is only as good as your data set. So depending on the type of data you’re using, as well as your goals for machine learning, you can break machine learning down into three general categories: supervised learning, unsupervised learning, and reinforcement learning.
Supervised learning predicts patterns in known data. Unsupervised learning finds hidden patterns or clusters within unknown data, and in reinforcement learning, machines make decisions based on dynamic data.
Supervised learning
Supervised machine learning uses data sets that are well-labeled with clear input and output variables. The machines apply this data to predict the output of new data, often with the help of support vector machines for classification, regression analysis, and identifying outliers. In this model, you’re giving machines input and output variables since you have a sense of what results to expect from the data.
Facial recognition technology is a popular application of supervised learning since technology companies like Apple or Facebook have trained machines on identifying millions of faces. So when you take a new picture, the machines can usually correctly predict the identity of the faces in new faces within a database.
Unsupervised learning
If you’re using unlabeled data, unsupervised machine learning might be a better type of machine learning to use for the validation of your data set. Unsupervised learning uses machine learning algorithms to identify unlabeled clusters of data.
One practical use of unsupervised learning would be recommendation sections like recommendation engines for online shopping or music. While the algorithms might not always correctly guess what their customers want to watch or listen to, they can identify big patterns in the data. For example, people who like watching Star Wars might also like watching the Mandalorian, versus a Jane Austen period piece. But many people might enjoy both. You’ll also see applications of unsupervised learning when you receive personalized product recommendations while online shopping, or even in your social media feeds.
Reinforcement learning
Reinforcement learning is a dynamic process and incorporates a trial-and-error approach to train machines. Data scientists will use it when they need to make a decision point and have several different options to choose from. A room-cleaning robot uses reinforcement learning because once it bumps into one obstacle, it can choose several different directions based on the environment. The data set aka the room layout might constantly change, causing the machine to constantly adjust its trajectory.
The Learning to Run project from deepsense.ai in collaboration with Stanford University is another more complex example of reinforcement learning. They created a machine that had to learn all of the nuanced motions of an active runner, so the machines had to follow a sequence of dynamic events to create movement like jumping.
Neural networks and deep learning
While these are the three basic subsets of machine learning, (and don’t forget semi-supervised learning, which is a hybrid of supervised and unsupervised learning), perhaps one of the most talked-about machine learning applications would be deep learning. There are thousands of other more robust resources on these topics, and since this article is a general intro to machine learning, we won’t get into the details here, but here are a few basics so you can get started.
Deep learning is considered scalable machine learning since it’s not as dependent on human intervention and can tackle large data sets. It’s a type of supervised machine learning algorithm that consists of neural networks similar to the human brain. Neural networks form the structure of deep learning algorithms, though the “deep” part of deep machine learning comes from the neural network layers.
These neural networks, or artificial neural networks, are a form of reinforcement learning. Like other forms of machine learning, they receive data, recognize patterns, and predict the outputs for similar data, and exist in a similar formation to the neurons in the human brain with a layer that receives data, a layer for output data, and several other connected hidden layers where computation occurs. Because deep learning algorithms can process such significant quantities of data without as much human intervention, data scientists are continuing to develop this form of technology.
What are the steps of machine learning?
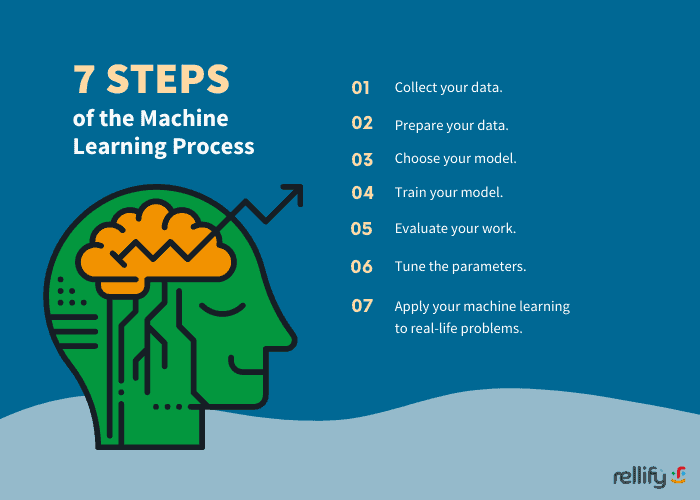
Regardless of the specific type of machine learning algorithms you’re using, when you’re solving a problem with machine learning, you’ll go through the following seven steps.
- Collect your data.
- Prepare your data.
- Choose your model.
- Train the model.
- Evaluate your work.
- Tune the parameters.
- Apply your machine learning to real-life problems.
1. Collect your data.
At the most basic level, what do you want to train the machine to learn? What are your data points? Get your sample data in order so you can train the machines to know what’s relevant. If you’re trying to train your machine to understand the difference between horses and cows, you’ll need to get lots of images of these two different types of animals.
Remember that your machines are only as good as the data you give them, so if you have a bad data set, you’re not going to get quality results.
2. Prepare your data.
Now that you have your data, how are you going to change that into training data so the machine understands what to do? You want to make sure you don’t give the machine duplicate data, and that your data is balanced between different results. So you don’t want to give the machine 50,000 horse images and two cow ones if you want to train your machines effectively.
3. Choose your model.
Are you going to use deep learning or convolutional neural networks? Perhaps a logistic regression or Bayesian Classifiers? Your data set and the problem you’re solving for will determine which machine learning model you will incorporate into your work. For more complex data applications, you might start with unsupervised learning before moving to a supervised learning model. Since you want to get the best outcome for analyzing your data, experimenting with different algorithms might give you the strongest results.
4. Train the model.
In this step, your machine will evaluate your data to discover patterns and make predictions. You’ll split the dataset into smaller testing sets and different parameters to fine-tune your results.
5. Evaluate your work.
How accurately is the machine evaluating your data input? What are your output values? To find out, you’ll want to test your model’s performance on new data to measure your results. If your results are under 90% accurate, you might need to tweak your model again.
6. Tune the parameters
If your outcome isn’t quite as accurate as you would like, retrain your machines with new parameters, and test the model accuracy again. How can you get better results from the data you have?
7. Apply your machine learning to real-life problems
Congratulations! If your machine learning model is working effectively, you’re ready to test it out on new data. You will need a practical way to connect your working models to real life applications, such as your marketing or corporate communications teams producing content that’s relevant to your target audience!
rellify and machine learning
If you look around the content marketing space, nearly every tool mentions that it uses AI to perform tasks from article topic selection to writing articles. But while artificial intelligence incorporates machines making decisions, human intervention still matters, as does the quality of data.
That’s why rellify’s machine learning process is so transformative. Rather than using generic website data from the entire Internet, rellify experts research your business, industry, and competitors offerings using machine selected data that are unique to your business. Rellify then uses a deep learning process to build exclusive neural networks to apply to your corporate communications and ensure your teams produce the most relevant content to achieve your business goals. Contact us to learn more.