
Zuletzt aktualisiert vor 28 September, 2023 | Veröffentlicht: 27 September, 2023
aus: AI MAG, September 2023
Obwohl das Konzept einer „Künstlichen Intelligenz“ mindestens so alt ist wie die Turing-Maschine (also aus den 30er Jahren des letzten Jahrhunderts stammt), ist Künstliche Intelligenz erst mit dem Launch von ChatGPT im vergangenen November zur Haushaltsvokabel in Wirtschaft und Politik, aber auch im Alltag geworden. Erst durch den genialen Schachzug von OpenAI, dieser komplexen Technologie ein extrem einfach zu bedienendes konversationelles User Interface vorzuschalten und diese Lösung dann kostenlos jedermann und jederfrau zur Verfügung zu stellen, rückten generative KI oder Large Language Models (LLMs) in den Fokus der breiten Öffentlichkeit.
Denn die einfache Nutzung und die auf den ersten Blick beeindruckenden Ergebnisse von ChatGPT begeistern und faszinieren die Massen ebenso wie Business Professionals. Fragt man ChatGPT, wofür man es benutzen könne, nennt die Maschine folgende Aktivitäten: Textgenerierung, Fragen beantworten, Textzusammenfassung, Übersetzungen, Programmierung und Codieren, Lernunterstützung, Idee-Generierung, Kommunikation und Dialog, Textanalyse, Gesprächspartner, Unterhaltung.*
Kurz gesagt, ChatGPT scheint ein Alleskönner für eine Fülle von Aufgaben im Zusammenhang mit Sprache zu sein. Kein Wunder also, dass sich insbesondere Marketers, deren Geschäft es ja ist, „Geschichten“ zu entwickeln und an den Mann oder die Frau zu bringen, sich auf das kostenlose Tool gestürzt haben. Laut einer aktuellen McKinsey-Studie nutzen mittlerweile 14% der Unternehmen generative KI für Marketing und Sales. Sie nutzen KIs wie ChatGPT, um Blogartikel oder Social Media Posts zu schreiben, Inhaltsstrategien zu entwickeln, Anschreiben zu erstellen etc.
Doch der Hype um die „Wunderwaffe“ LLM hat sich mittlerweile ein wenig gelegt. Denn je mehr Inhalte mit der Maschine entwickelt wurden, desto deutlicher wurden ihre Schwächen (siehe unten). Viele Unternehmen untersagen daher bereits die Nutzung von ChatGPT für Unternehmenszwecke. Parallel verbreitet sich die Einschätzung, die „Alleskönner“ ChatGPT oder sein Wettbewerber Bard seien in Wirklichkeit „Nichtsrichtigkönner“, die zwar für den Hausgebrauch taugten, Unternehmen aber unter Umständen ernsthaft schaden könnten, wenn sie ungeprüft eingesetzt würden.
Auch in der KI-Branche macht sich mittlerweile die Einsicht breit, wie DER SPIEGEL in Ausgabe 30/2023 schrieb, dass „OpenAI das KI-Zeitalter nicht dominieren wird“. Selbst Sam Altman, Chef von Open AI, glaube laut SPIEGEL, wir seien „am Ende der Ära dieser gigantischen Modelle angekommen“. Kein Wunder also, dass der Trend dahin ginge, kleinere, spezialisierte Modelle zu entwickeln – also Maßanzüge statt Massenware anzubieten.
Einer dieser „Maßanzüge“ sind sogenannte Enterprise KIs, ein Beispiel werden wir im Folgenden vorstellen. Zunächst aber wollen wir uns erstmal genauer ansehen, was ein Large Language Model eigentlich ist, und was die Schwächen und Risiken seines Einsatzes sind.
Was ist eigentlich ein Large Language Model?
Auch diese Frage kann ChatGPT gut beantworten: Ein Large Language Model (LLM) ist ein fortschrittlicher Typ von künstlicher Intelligenz (KI), der entwickelt wurde, um menschenähnlichen Text in natürlicher Sprache zu verstehen und zu generieren. Diese Modelle basieren auf tiefen neuronalen Netzwerken, die darauf trainiert sind, riesige Mengen an Textdaten zu verarbeiten und darauf basierende Aufgaben auszuführen. Eines der bekanntesten Beispiele für ein Large Language Model ist GPT-3 (Generative Pre-trained Transformer 3), das von OpenAI entwickelt wurde. […] Große Sprachmodelle wie GPT-3 sind in verschiedenen Bereichen wie maschinellem Übersetzen, Textzusammenfassung, Textklassifikation, Chatbots und sogar bei der Generierung von kreativem Inhalt weit verbreitet. Sie sind jedoch auch Gegenstand ethischer und gesellschaftlicher Diskussionen, da ihre Fähigkeiten zur Texterzeugung und -manipulation auch Missbrauchspotenzial bergen können.*
Das sagt ChatGPT also über sich selbst. Es ist eine sehr oberflächliche Erklärung, in Wirklichkeit ist die Sache wesentlich komplexer. Aber eines wird hier schon sichtbar: Die große Schwäche der LLMs ist einerseits ihre Belanglosigkeit (die Antwort grenzt ans Banale) und andererseits ihr Selbstbewusstsein (die Antwort klingt, als sei sie erschöpfend).
Schwächen und Risiken der LLMs
Zunächst muss an dieser Stelle klargestellt werden, dass LLMs weder über ein Sprachverständnis im eigentlichen Sinne noch über eine Vorstellung von „wahr“ und falsch“ verfügen: Alle Ausgaben eines LLMs sind lediglich die „wahrscheinlichste“ Aneinanderreihung von Worten im Hinblick auf den eingegebenen Prompt (die Frage oder Aufgabenstellung). Dadurch, dass diese Wahrscheinlichkeit vor dem Hintergrund von 175 Milliarden Datenpunkten (GPT-3) oft sehr hoch ist, entsteht der Eindruck, die Maschine würde die Frage verstehen und inhaltlich beantworten – das ist aber faktisch nicht der Fall! Vereinfacht gesagt liefert ein LLM auf eine Frage eine Zeichenkette, die – laut ihrem „Gedächtnis“ aus 175 Milliarden „Ereignissen“ – am häufigsten auf die Eingangs-Zeichenkette (die Frage) folgen würde. Hinzu kommt noch, dass die zugrundeliegenden Daten nicht aktuell sind. Im Falle von ChatGPT berücksichtigt das LLM nur Daten bis zum Entstehungsjahr 2021 – das heißt, dass die Maschine zu Themen, die erst danach im Web aufgetaucht sind, wenig bis nichts sagen kann.
Daraus folgt natürlich nicht, dass die Antworten eines LLMs immer falsch oder nur zufällig richtig wären. Ganz im Gegenteil – durch die hohe Grundgesamtheit an Daten sind sie in den allermeisten Fällen durchaus völlig richtig. Das Problem, das Unternehmen jedoch großes Unwohl bereitet, ist aber, das man nicht weiß, wann die Maschine richtig liegt und wann nicht. Es gilt im Prinzip, jede Aussage zu überprüfen.
Ein weiteres Problem, ist ein Phänomen, das man als „Tendenziosität“ bezeichnen kann. Die Maschine übernimmt zwangsläufig Tendenzen des ihr zugrundeliegenden Materials. So kann es durchaus dazu kommen, dass ChatGPT eine politisch nicht korrekte Aussage trifft, weil in seinem Datenbestand zu diesem Thema überwiegend politisch nicht korrekte Inhalte vorliegen. Das kann Unternehmen, wenn diese solche Aussagen publizieren, schnell einen „Shitstorm“ einhandeln. Auch Markenwerte kennt ein LLM natürlich nicht und kann diese folgerichtig auch in seinen Ausgaben nicht abbilden.
Eine weitere Sorge ist urheberrechtlicher Natur. Was, wenn ChatGPT einen Inhalt liefert, der urheberrechtlich geschützt ist? Dann drohen Rechtsstreitigkeiten, wie sie in den USA bereits zu Dutzenden gegen ChatGPT und Co. anhängig sind.
Und nicht zuletzt mangelnde Kreativität. ChatGPT sagt (s.o.) von sich selbst, es sei gut zur Ideen-Generierung geeignet. Doch die präsentierten Ideen sind ja systematisch betrachtet nur ein Aufguss der im Datenbestand vorhandenen Ansätze und damit wenig originell. Wer z.B. ChatGPT fragt, worüber er zu einem bestimmten Thema schreiben könne, erhält sehr generische Vorschläge (mehr dazu weiter unten), auf die er sicher auch selbst schnell gekommen wäre.
Kurz gesagt – Unternehmen können nicht einfach Inhalte mit ChatGPT erstellen und dann ungeprüft verwenden. Sie müssen zumindest einen Prozess zur Qualitätssicherheit definieren und in die Tat umsetzen.
Auswege aus der LLM-Problematik
Wenn man einsieht, dass man als Unternehmen ChatGPT & Co. aus oben genannten Gründen nicht blind nutzen kann, bleiben eigentlich nur drei Strategien:
Pimp my ride
Unternehmen tunen die Big-Tech-LLMs mit Prompting-Workflow-Tools. So erhalten sie zwar bessere Ergebnisse, die auch ihre Markensprache widerspiegeln können, die Qualität der Ergebnisse bleibt jedoch abhängig von den genutzten geschlossenen LLMs und ständiger (Fein-) Abstimmung ihrer Prompts. Zudem brauchen sie einen zusätzlichen, aus dem Budget zu finanzierenden Prompt-Engineer.
DYI – Do it yourself
Unternehmen entwickeln im Hause ihre eigene KI z.B. mit Open-Source-Modellen. Wenn sie die richtigen Daten einkaufen, sind diese relevanter und die Antworten entsprechend genauer. Natürlich brauchen sie dazu eine professionelle KI-Abteilung, ein belastbares Budget und müssen ein großes IT-Projekt steuern und zum Erfolg führen. Für die meisten Unternehmen ist das schlicht nicht darstellbar.
Enterprise KI / KI-as-a-Service
Unternehmen erwerben eine proprietäre, themen-spezifische, speziell für sie entwickelte KI wie das Neuraverse von Rellify. Auf Basis genau definierter, relevanter und stets aktueller Daten nutzen sie damit eine exklusive, maßgeschneiderte Lösung mit voller, alleiniger Zugriffskontrolle.
Was unterscheidet eine Enterprise KI von einem LLM?
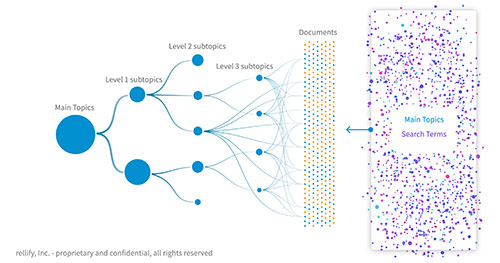
Basis einer Enterprise KI: Themen- und unternehmensspezifische Daten
Der wichtigste Unterschied zwischen einer themenspezifischen KI wie dem Neuraverse und den großen geschlossenen LLMs wie ChatGPT liegt in den zugrundeliegenden Daten. Im Unterschied zu dem quasi allumfassenden Datenmischmasch der großen LLMs werden die Daten für ein Neuraverse für jeden Kunden einzeln mit Crawlern und Machine Learning erstellt. Das System crawlt die URLs des Unternehmens und seiner Wettbewerber und analysiert mit seinem zum Patent angemeldeten Deep Machine Learning riesige Mengen verwandter Dokumente. So werden zig-Tausende von Schlüsselwörtern und Phrasen sowie Millionen von Verbindungen zwischen ihnen erkannt. Alle relevanten Suchbegriffe werden anschließend zugewiesen. Dann clustert die KI die Daten nach Hauptthemen, Unterthemen der Ebene 1, Unterthemen der Ebene 2 und Unterthemen der Ebene 3. Dabei werden Millionen Datenpunkte berücksichtigt – es entsteht eine Analysetiefe, die so kein menschliches Team leisten könnte.
Die Ergebnisse dieses Prozesses werden in der browser-basierten Content Intelligence Application bereitgestellt. Dort sieht man auf einen Blick alle Themen, die ausweislich der KI-Analyse strategische Bedeutung haben und bei entsprechender Bearbeitung die Themenführerschaft sichern und organischen Traffic generieren. Die Erstellung von Inhalten auf Basis der durch das Neuraverse bereitgestellten Content Intelligence erfolgt dann in einem durchgehenden, von KI geführtem und unterstütztem Prozess direkt in der Applikation.
Vorteile einer Enterprise KI-as-a-Service

Massanzug Enterprise KI: Passt einfach besser!
Der Vorteil eines Neuraverse liegt in den zugrundeliegenden Daten. Da das System exklusiv auf Inhalten beruht, die für die Themen des beauftragenden Unternehmens von strategischer Relevanz sind, entsteht eine echte Fachexperten-KI. Deren Nutzer verstehen nicht nur ihren Content und den ihrer Konkurrenten wie nie zuvor. Sie sehen ihre Content-Marktanteile und Sichtbarkeit auf einen Blick und wissen stets, worüber und warum sie darüber schreiben müssen – ohne ständige mühsame Analysen durchführen zu müssen.
Die KI hilft aber auch im geführten Schreibprozess der Content Intelligence Application. So sehen die Nutzer im ersten Schritt auf einen Blick die strategischen Themen, die basierend auf den Findings des Neuraverse, bearbeitet werden sollten. Wenn ein Thema ausgewählt ist, kann der Autor die Artikelstruktur per Drag & Drop zusammenstellen. Oder er lässt mit Klick auf einen entsprechenden Button die KI aus dem gewählten Thema und den zugeordneten Keywords eine Artikelstruktur entwickeln.
Beim Schreiben selbst hat er die Möglichkeit, den ganzen Artikel automatisch erstellen zu lassen oder je (Unterüberschrift) einen Absatz automatisch generieren zu lassen. Hier zeigt sich ein weiterer wichtiger Vorteil eines Neuraverse: Bei der Automated AI Content Generation wird das dahinterliegende LLM (aktuell GPT-4) mit Prompts gefüttert, in denen das gesamte Briefing, also Inhaltsstruktur, Keywords, Fragen etc. berücksichtigt ist. Das heißt, das LLM erhält einen optimierten Prompt mit den exakten, relevanten Inputs für den zu generierenden Text, was eine maximale Qualität seines Outputs garantiert.
Um bei der anfangs verwendeten Analogie zu bleiben, kann man auch sagen, dass eine proprietäre Enterprise KI-as-a-Service wie ein Maßanzug faltenfrei ist, Passgenauigkeit bietet und den Träger insgesamt einfach besser aussehen lässt als den Nutzer eines geschlossenen LLMs. Und das ist in einem Marktumfeld, in dem Large Language Models zu einer stetig ansteigenden Flut von Inhalten führen, die oft um dieselben Leser buhlen, ein echter Wettbewerbsvorteil.
*kursiv gesetzter Text ist zitiert aus ChatGPT!
Über den Autor


Sebastian Paulke
Global Director Corporate Communication, Rellify
Seit über 20 Jahren arbeitet Sebastian Paulke als freier Journalist, Innovationstechnologie-Analyst, Online-Kommunikationsberater und Autor für internationale Unternehmen aller Größenordnungen. Seine Kernkompetenz ist, Innovationstechnologien in den neuen Medien und Kanälen Aufmerksamkeit und Verständnis zu verschaffen…